Abstract
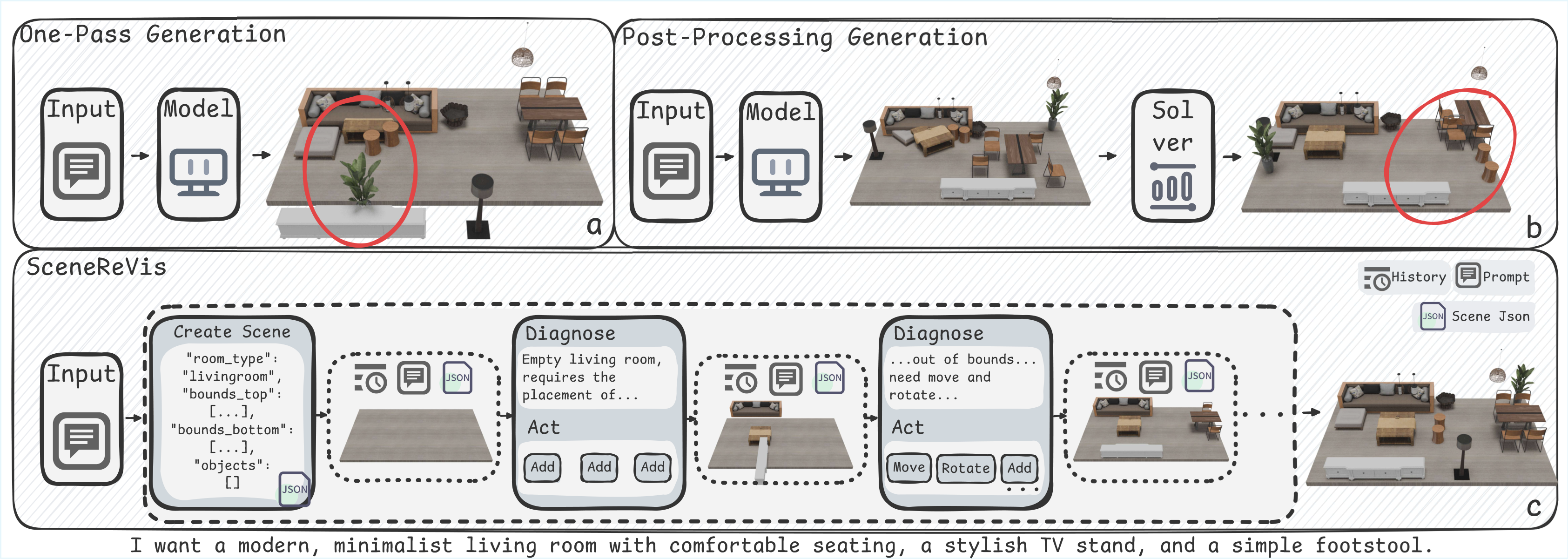
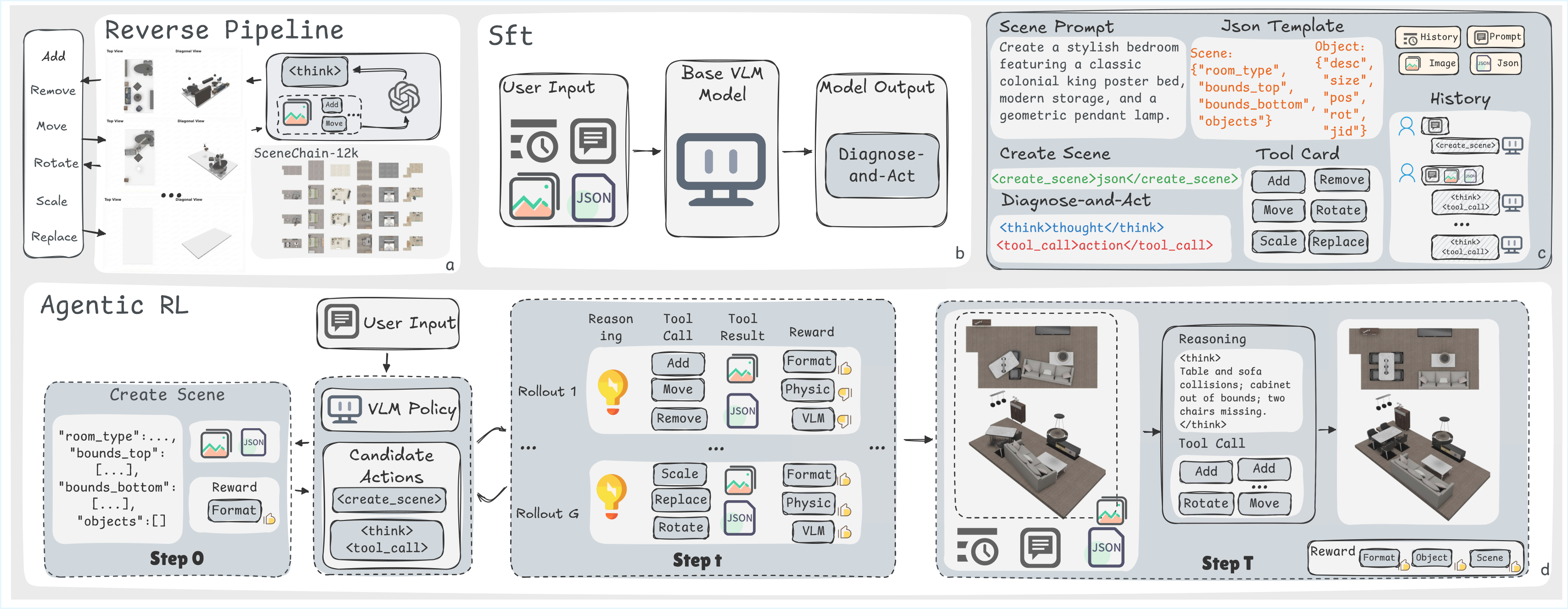
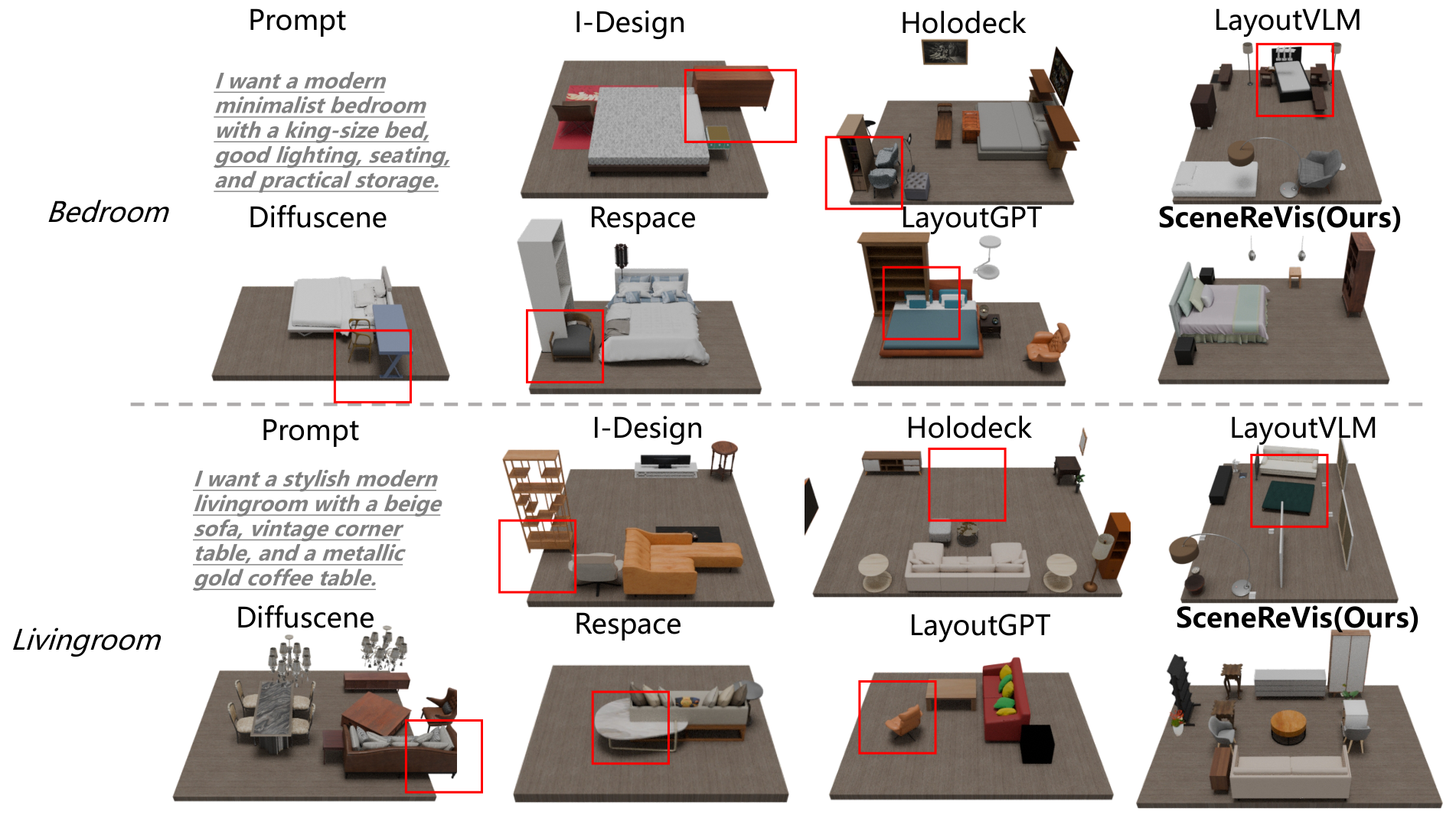
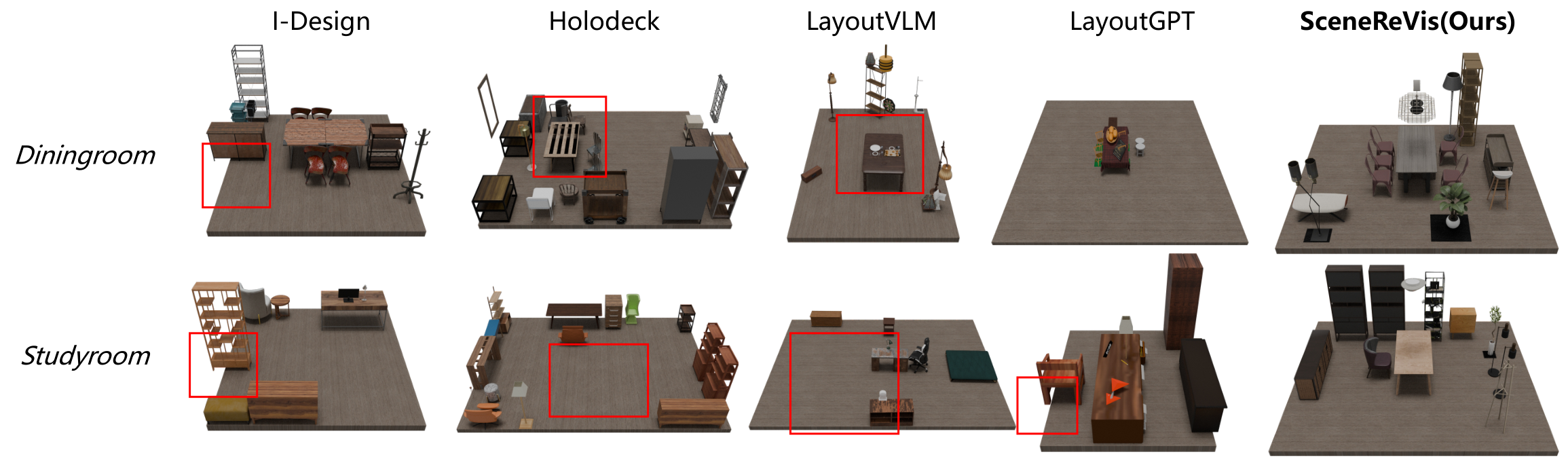
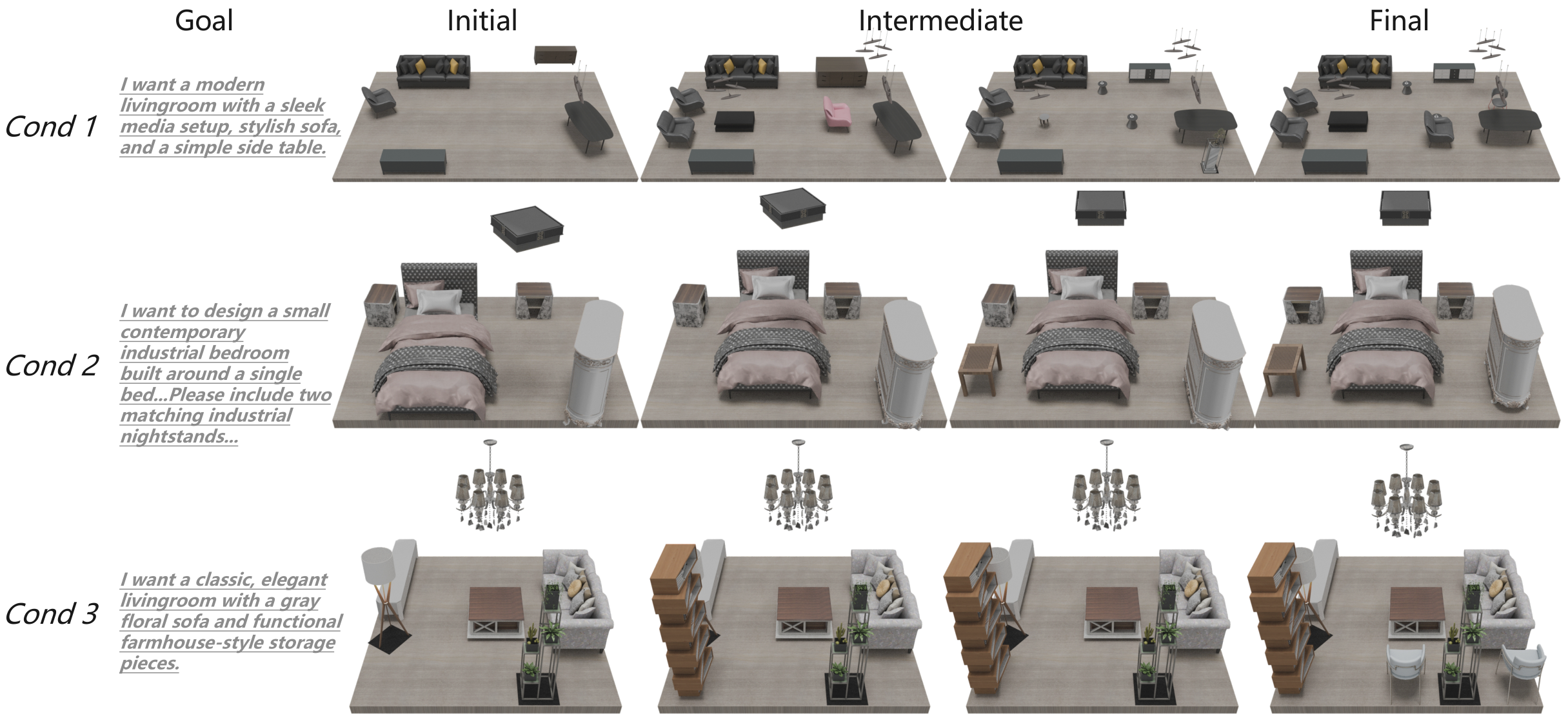
Current one-pass 3D scene synthesis methods often suffer from spatial hallucinations, such as collisions, due to a lack of deliberative reasoning. To bridge this gap, we introduce SceneReVis, a vision-grounded self-reflection framework that employs an iterative “diagnose-and-act” loop to explicitly intercept and resolve spatial conflicts using multi-modal feedback. To support this step-wise paradigm, we construct SceneChain-12k, a large-scale dataset of causal construction trajectories derived through a novel reverse engineering pipeline. We further propose a two-stage training recipe that transitions from Supervised Fine-Tuning to Agentic Reinforcement Learning, evolving the model into an active spatial planner. Extensive experiments demonstrate that SceneReVis achieves state-of-the-art performance in high-fidelity generation and goal-oriented optimization, with robust generalization to long-tail domains.